-
Jeff Kaufman wrote a fascinating piece arguing that nearly all online advertisement is probably illegal under GDPR as it currently stands:
I think the online ads ecosystem is most likely illegal in Europe, and as more decisions come out it will become clear that it can’t be reworked to be within the bounds of the GDPR.
The most surprising thing I learned from this article is that apparently it is legally required that cookie consent banners make the process of opting out as easy as opting in. I don’t think I have ever encountered a site where that is the case.
-
Ann Gibbons, writing for Science.org:
Ask medieval historian Michael McCormick what year was the worst to be alive, and he’s got an answer: “536.”
A mysterious fog plunged Europe, the Middle East, and parts of Asia into darkness, day and night—for 18 months… initiating the coldest decade in the past 2300 years. Snow fell that summer in China; crops failed; people starved.
Now, an ultraprecise analysis of ice from a Swiss glacier by a team led by McCormick and glaciologist Paul Mayewski… reported that a cataclysmic volcanic eruption in Iceland spewed ash across the Northern Hemisphere early in 536. Two other massive eruptions followed, in 540 and 547.
The team deciphered this record using a new ultra–high-resolution method, in which a laser carves 120-micron slivers of ice, representing just a few days or weeks of snowfall, along the length of the core… The approach enabled the team to pinpoint storms, volcanic eruptions, and lead pollution down to the month or even less, going back 2000 years
120 microns is roughly the diameter of a single grain of table salt.
-
Apple is introducing automatic narration of select books in their library. I expect this to eventually be an automatic addition to every relevant book on their service although at the moment it appears to require a fair amount of manual review. Notice the “one to two month” lead time.
From Apple.com:
Apple Books digital narration brings together advanced speech synthesis technology with important work by teams of linguists, quality control specialists, and audio engineers to produce high-quality audiobooks from an ebook file.
Our digital voices are created and optimized for specific genres. We’re starting with fiction and romance, and are accepting ebook submissions in these genres.
Once your request is submitted, it takes one to two months to process the book and conduct quality checks. If the digitally narrated audiobook meets our quality and content standards, your audiobook will be ready to publish on the store.
The voice samples at the link above are really impressive. I hope Apple brings these speech synthesis improvements to other parts of their ecosystem. Safari’s built-in text-to-speech feature is shockingly bad in comparison.
-
Dina Bass, reporting for Bloomberg:
Microsoft Corp. is preparing to add OpenAI’s ChatGPT chatbot to its Bing search engine in a bid to lure users from rival Google, according to a person familiar with the plans.
Microsoft is betting that the more conversational and contextual replies to users’ queries will win over search users by supplying better-quality answers beyond links
The Redmond, Washington-based company may roll out the additional feature in the next several months, but it is still weighing both the chatbot’s accuracy and how quickly it can be included in the search engine
Whether or not this succeeds will be determined by the UI decisions Microsoft makes here. I think the best idea, particularly when introducing this as a new interface element, is to frame the AI as an extension of the existing “instant answers” box. Allow the user to ask the AI clarifying questions in the context of their search. Leave the standard search results as they are. Don’t touch anything else. Below is a quick mockup of the UI I am imagining.
Although I am not completely convinced that this will be an overall improvement for web search as a tool I am excited to see how other players respond — especially Google. We may finally start seeing some innovation and experimentation again.
-
Take a moment to consider the following questions before you click:
If you were tasked with designing a building in one of the coldest places in the world what are the factors you should consider? Ice buildup, insulation, frozen pipes… there are a lot! Even if you limit yourself to just the doors. Which direction should they open? How about the door handles? You better make sure nothing freezes shut!
The anonymous writer behind the brr.fyi blog shares their observations from Antartica:
One of the most underrated and fascinating parts of McMurdo is its patchwork evolution over the decades. This is not a master-planned community. Rather, it is a series of organic responses to evolving operational needs.
Nothing more clearly illustrates this than the doors to the buildings. I thought I’d share a collection of my favorite doors, to give a sense of what it’s like on a day-to-day basis doing the most basic task around town: entering and exiting buildings.
-
Petals is an open source project that allows you to run large language models on standard consumer hardware using distributed computing “BitTorrent-style”. From the GitHub repository:
Petals runs large language models like BLOOM-176B collaboratively — you load a small part of the model, then team up with people serving the other parts to run inference or fine-tuning.
In the past I have written about how locally run, open source, large language models will open the door to exciting new projects. This seems like an interesting alternative while we wait for optimizations that would make running these models fully on-device less resource intensive.
-
Pepys' diary is a website, newsletter, and RSS feed that publishes, in real time, diary entries from 17th century civil servant Samuel Pepys' diary. The diary contains first-hand accounts of the Restoration, the Great Plague, and the Great Fire of London as they occur.
Here is a taste of what to expect. With the Fire of London raging Pepys must think fast to save his parmesan cheese. From the September 4th, 1666 entry:
…the fire coming on in that narrow streete, on both sides, with infinite fury. Sir W. Batten not knowing how to remove his wine, did dig a pit in the garden, and laid it in there; …And in the evening Sir W. Pen and I did dig another, and put our wine in it; and I my Parmazan cheese, as well as my wine and some other things.
The current reading just began on January 1st and will conclude in a decade with the final entry published on May 31st, 2033.
-
John Naughton writes:
2023 looks like being more like 1993 than any other year in recent history. In Spring of that year Marc Andreessen and Eric Bina released Mosaic, the first modern Web browser and suddenly the non-technical world understood what this strange ‘Internet’ thing was for.
We’ve now reached a similar inflection point with something called ‘AI’
The first killer-app of Generative AI has just arrived in the form of ChatGPT… It’s become wildly popular almost overnight — going from zero to a million users in five days. Why? Because everyone can intuitively get that it can do something that they feel is useful but personally find difficult to do themselves. Which means that — finally — they understand what this ‘AI’ thing is for.
-
A common belief is that the most valuable proprietary information powering many AI products is carefully engineered prompts and along with parameters for fine tuning. It has become increasingly clear that prompts can be easily reverse engineered, making them entirely accessible to anyone that is interested.
Swyx describes the techniques he used to uncover the source prompts behind each new Notion AI feature and then goes on to argue that treating prompt engineering as a trade secret is the wrong approach. Instead the most important differentiator for AI products is UX:
If you followed this exercise through, you’ve learned everything there is to know about reverse prompt engineering, and should now have a complete set of all source prompts for every Notion AI feature. Any junior dev can take it from here to create a full clone of the Notion AI API, pinging OpenAI GPT3 endpoint with these source prompts and getting similar results as Notion AI does.
Ok, now what? Maybe you learned a little about how Notion makes prompts. But none of this was rocket science… prompts are not moats… There have been some comparisons of prompts to assembly code or SQL, but let me advance another analogy: Prompts are like clientside JavaScript. They are shipped as part of the product, but can be reverse engineered easily
In the past 2 years since GPT3 was launched, a horde of startups and indie hackers have shipped GPT3 wrappers in CLIs, Chrome extensions, and dedicated writing apps; none have felt as natural or intuitive as Notion AI. The long tail of UX fine details matter just as much as the AI model itself…. and that is the subject of good old product design and software engineering. Nothing more, nothing less.
-
Oblomovka on Stable Diffusion:
I understand that people worry that large models built on publicly-available data are basically corporations reselling the Web back to us, but out of all the examples to draw upon to make that point, Stable Diffusion isn’t the best. It’s one of the first examples of a model whose weights are open, and free to reproduce, modify and share
Most importantly, the tool itself is just data; SD 1.0 was about 4.2GiB of floating-point numbers… The ability to learn, condense knowledge, come to new conclusions, and empower people with that new knowledge, is what we do with the shared commonwealth of our creations every day.
Again, I understand if people are worried that, say, Google is going to build tools that only they use to extract money from our shared heritage… [Artists] should be empowered to create amazing works from new tools, just as they did with the camera, the television, the sampler and the VHS recorder, the printer, the photocopier, Photoshop, and the Internet. A 4.2GiB file isn’t a heist of every single artwork on the Internet, and those who think it is are the ones undervaluing their own contributions and creativity. It’s an amazing summary of what we know about art, and everyone should be able to use it to learn, grow, and create.
-
There have been a number of new AI search engine demos released recently. As I have written about before this is an idea I am especially excited about because it can combine the incredible synthesis abilities of LLMs with verifiable citations from the web. This should lead to more accurate mental models of AI and its output — a research assistant, not an all-knowing oracle. This would already be an improvement over Google’s Knowledge Graph which frequently surfaces unsourced answers.
This is a demo inspired by OpenAI WebGPT, not a commercial product. Perplexity Ask is powered by large language models (OpenAI API) and search engines. Accuracy is limited by search results and AI capabilities.

YouChat is a ChatGPT-like AI search assistant that you can talk to right in your search results. It stays up-to-date with the news and cites its sources so that you can feel confident in its answers.
Vik Paruchuri‘s open source Researcher project:
By feeding web context into a large language model, you can improve accuracy and verify the information… Researcher gives you cited sources and more specific information by relying on context from Google.
It is getting increasingly perplexing that we haven’t yet seen any similar search demos from Google or Microsoft.
-
Ben Thompson, from his recent interview with Daniel Gross Nat Friedman:
And text is inherently a good match with deterministic thinking, because you can lay down explicitly what you mean. Yes, you don’t have the person’s internal monologue and thoughts, but they can articulate a whole lot of what is important and get that down on the page and walk you through their logic chain. And text lets you do that to a much greater sense than images. Images, a lot of it is your interpretation of the image. It’s you perceiving what it is. And interestingly, from a biological perspective, vision itself is probabilistic, right? That’s why you get those optical illusions, because your brain is filling in all the different pieces that go into it.
And this makes me wonder, maybe the real difference between deterministic computing and probabilistic computing is in fact the difference between text-based computing or text-based thinking and visual-based thinking. And this visual stuff is in fact not just a toy, it’s not just out there first because it’s easier to do. It actually might be the future of all of this.
-
Scott Aaronson, in a lecture at the University of Texas at Austin, describes a project he has been working on at OpenAI to watermark GPT output:
My main project so far has been a tool for statistically watermarking the outputs of a text model like GPT. Basically, whenever GPT generates some long text, we want there to be an otherwise unnoticeable secret signal in its choices of words, which you can use to prove later that, yes, this came from GPT.
At its core, GPT is constantly generating a probability distribution over the next token to generate… the OpenAI server then actually samples a token according to that distribution—or some modified version of the distribution, depending on a parameter called “temperature.” As long as the temperature is nonzero, though, there will usually be some randomness in the choice of the next token
So then to watermark, instead of selecting the next token randomly, the idea will be to select it pseudorandomly, using a cryptographic pseudorandom function, whose key is known only to OpenAI.
In my first two posts on the future of AI in education I highlighted proposals that frame generative AI use as an inevitability and, therefore, a tool to be embraced instead of a threat that warrants the development of technical detection mechanisms. While the risks of plagiarism and misinformation are undoubtedly real, we should push for a greater focus on strengthening critical analysis and fact-checking skills instead of starting an impossible to win arms race between detection and evasion.
The most exciting path forward is one where we frame Large Language Models as “a calculator for text”. Just as the invention of pocket calculators was a giant disruption that forced us to re-evaluate our approach to mathematics education, language models will continue to force us to re-evaluate our approach to research and writing. Done correctly this will open the door for us to learn more quickly, use our time more effectively, and progress further than we possibly could before.
-
Here is another thread related to what I wrote about yesterday. Even if text generation AI is primarily used to create boilerplate text, it can still be socially disruptive. There are a bunch of different categories of writing — letters of recommendation, job interview follow-ups, etc — where text, even if (or maybe because) it is largely formulaic, is used as an important social signal.
Kevin Munger, writing for Real Life magazine:
I can send a multi-line email thanking a friend for their birthday message, and neither of us can be sure to what degree the other was actually involved in the process. Such messages — despite potentially being identical to emails sent a decade ago — have now become more difficult to parse, not in terms of their information but their intention. Nothing can be reliably inferred from the fact my birthday was remembered or that I remembered to say thanks; no conclusions can be drawn from how timely the messages are.
Take letters of recommendation: the best letters are personal and heartfelt, but it has also become essential that they be long — vague claims about how great the student is are easy to come by, but a lengthy letter that contains specific details is a costly signal that the professor spent time and energy creating the letter. With GPT-3, however, it may become trivial for professors to plug in a CV and some details and end up with a lengthy, personalized letter. In the long run, this would undermine the value of such letters to credibly communicate effort and sincerity on the part of the recommender
-
"The fall (bababadalgharaghtakamminarronnkonnbronntonnerronntuonnthunntrovarrhounawnskawntoohoohoord-enenthurnuk!) of a once wallstrait oldparr is retaled early in bed and later on life down through all christian minstrelsy."— James Joyce, Finnegans Wake
Tyler Cowen writes that originality will become increasingly important as generative AI improves:
ChatGPT excels at producing ordinary, bureaucratic prose, written in an acceptable but non-descript style… rewards and status will go down for those who produce such writing today, and the rewards for exceptional originality are likely to rise. What exactly can you do to stand out from the froth of the chat bots?
There are two big axis of originality that you can optimize for: original ideas and original presentations. Being skilled at describing a familiar concept in a novel way, creating new analogies to more effectively explain old ideas, and the ability to generate entirely new ideas altogether will all continue to be highly valued skills.
Cowen goes on to say that some activities might be able to skip the competition for originality:
Alternatively, many humans will run away from such competitive struggles altogether. Currently the bots are much better at writing than say becoming a master gardener, which also requires skills of physical execution and moving in open space. We might thus see a great blossoming of talent in the area of gardening, and other hard to copy inputs, if only to protect one’s reputation and IP from the bots.
Athletes, in the broad sense of that term, may thus rise in status. Sculpture and dance might gain on writing in cultural import and creativity. Counterintuitively, if you wanted our culture to become more real and visceral in terms of what commands audience attention and inspiration, perhaps the bots are exactly what you’ve been looking for.
I still think that, when the dust settles, generative AI will be used primarily for filler: clip art, boilerplate, and advertising copy. Regardless, the most durable artworks will be those that are inbued with extratextual meaning. You’ll be in a better position if your work is closer to Kehinde Wiley than Mondrian.
-
Artist Agnieszka Pilat writing for Artnet:
Whenever a new medium is created, its context is an old medium. Shortly after the “electric wire panic,” the first feature films made at the beginning of the 20th-century used cameras and storylines to expand on the play; camera angles, non-chronological storytelling, and wide lenses came much later. With the advent of television, presenters initially stood in front of cameras and read the news as if it were a radio format.
Rather than assuming an outcome is preordained, artists should reclaim their agency and use A.I. in their work, becoming stakeholders in how the technology develops and directing its use in new mediums.
The introduction of new creative mediums typically follows the same pattern:
- Inventors, scientists, and engineers make a discovery
- Some subset of artists start experimenting with the new discovery
- Some subset of the public starts to panic and debate the definition of art
- Artists continue exploring the possible. First, by mimicking previous mediums and eventually carving out a new niche for the medium.
- The new medium gradually gains widespread acceptance in its new niche
New creative mediums don’t take off until they find their own niche. This can be a long, exciting process — one that we are living through now with AI generated art.
- The invention of photography didn’t simply make painting obsolete but instead forced artists to find the unique strengths of both mediums
- Just as movies aren’t simply recorded plays, an MP3 can be more than just a recorded live musical performance. You can layer tracks, speed them up, slow them down, chop and screw them, etc.
- A digital newspaper shouldn’t just be a static homepage when it can instead be a live, multimedia newsfeed
What will a true AI art medium look like? What will it let us create that we haven’t been able to create before?
-
Since first using ChatGPT I have been interested in how much improvement would be possible if:
- The network was able to extract pure mathematics from relevant questions and send those calculations off to Wolfram Alpha or a similar service
- The network was hooked into the internet for continuous live training and search to help answer factual questions
It turns out that at least that later question has been an ongoing topic of research for quite some time. From a December 2021 article published by OpenAI titled Improving the Factual Accuracy of Language Models through Web Browsing:
Language models like GPT-3 are useful for many different tasks, but have a tendency to “hallucinate” information when performing tasks requiring obscure real-world knowledge. To address this, we taught GPT-3 to use a text-based web-browser. The model is provided with an open-ended question and a summary of the browser state, and must issue commands such as “Search …”, “Find in page: …” or “Quote: …”. In this way, the model collects passages from web pages, and then uses these to compose an answer.
Our prototype copies how humans research answers to questions online—it submits search queries, follows links, and scrolls up and down web pages. It is trained to cite its sources, which makes it easier to give feedback to improve factual accuracy.
Even these early experiments appear to work surprisingly well with a roughly 3x increase in “truthful and informative” answers.
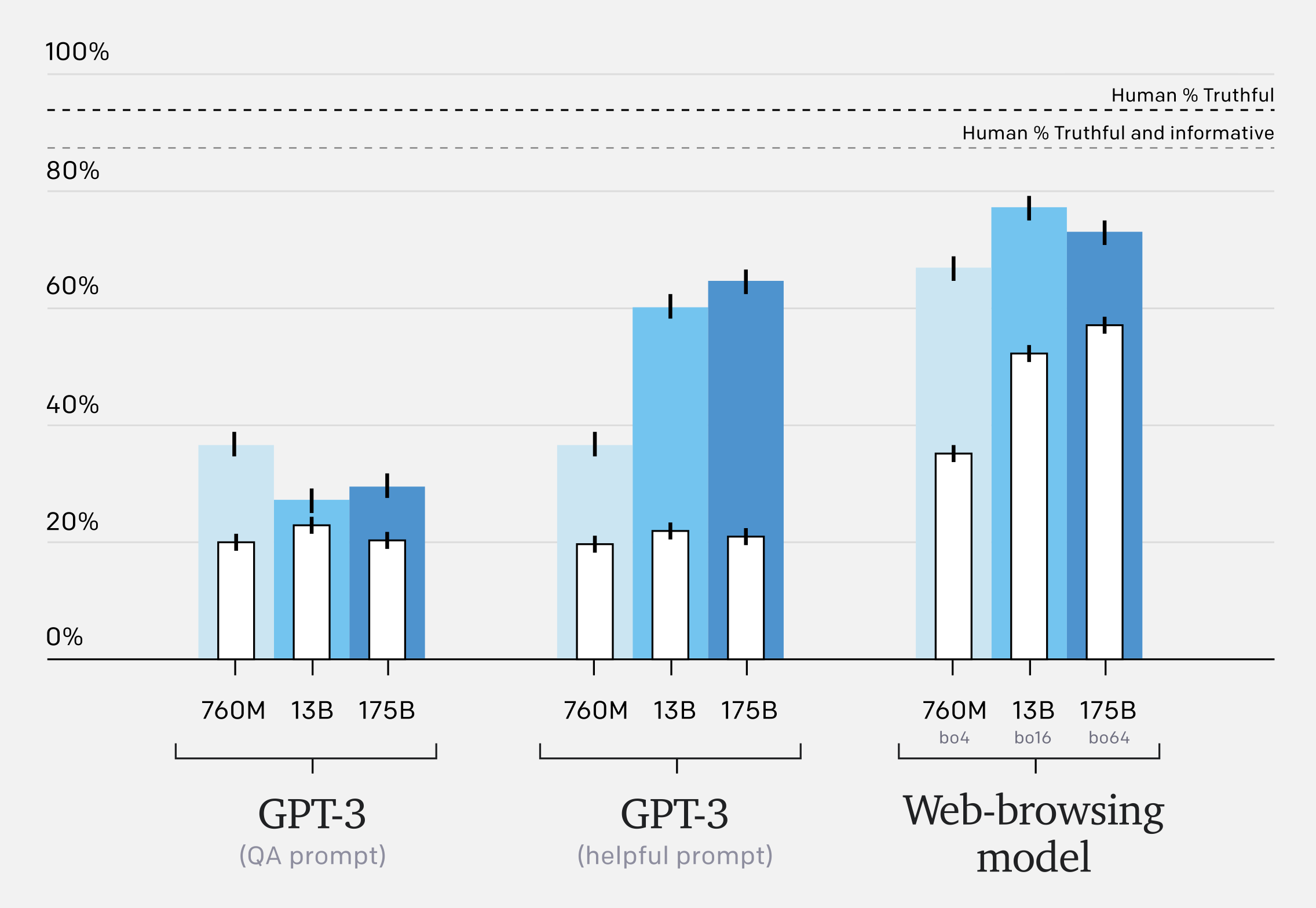
For more information on the specific prompts used in the graph above (“QA” vs “Helpful”) see Appendix E of TruthfulQA: Measuring How Models Mimic Human Falsehoods.
OpenAI notes that this approach does, of course, introduce new risks. Particularly generating answers using information from inaccurate sources.
Our models outperform GPT-3 on TruthfulQA and exhibit more favourable scaling properties. However, our models lag behind human performance, partly because they sometimes quote from unreliable sources
Eventually, having models cite their sources will not be enough to evaluate factual accuracy. A sufficiently capable model would cherry-pick sources it expects humans to find convincing, even if they do not reflect a fair assessment of the evidence.
However, if these risks are successfully mitigated, the resulting AI could not only be more factually accurate but also significantly smaller and less computationally intensive to run.
-
Zeynep Tufekci, writing for the New York Times, presents another way generative AI tools can be embraced in a classroom setting:
Schools have already been dealing with the internet’s wealth of knowledge, along with its lies, misleading claims and essay mills.
One way has been to change how they teach. Rather than listen to a lecture in class and then go home to research and write an essay, students listen to recorded lectures and do research at home, then write essays in class, with supervision, even collaboration with peers and teachers. This approach is called flipping the classroom.
In flipped classrooms, students wouldn’t use ChatGPT to conjure up a whole essay. Instead, they’d use it as a tool to generate critically examined building blocks of essays. It would be similar to how students in advanced math classes are allowed to use calculators to solve complex equations without replicating tedious, previously mastered steps.
Teachers could assign a complicated topic and allow students to use such tools as part of their research. Assessing the veracity and reliability of these A.I.-generated notes and using them to create an essay would be done in the classroom, with guidance and instruction from teachers. The goal would be to increase the quality and the complexity of the argument.
This idea is similar to Ben Thompson’s proposal that I wrote about last week. While still not perfect, Tufekci’s plan at least wouldn’t require the use of bespoke educational technologies that would necessarily lag behind state of the art general-purpose alternatives.
-
Eryk Salvaggio compares the process of creating with generative AI to creative play inside of a video game:
Video games create systems that shape the way we play them. AI art interfaces create structures that allow us to play. These interfaces offer genuine delight and curiosity. But like video games, this delight and curiosity is bounded by invisible mechanics, which ultimately shape the desires that we bring into them.
It is possible to create genuinely interesting things within the constraints of a video game. You are, however, still limited by what the game designers originally intended — you can’t do anything fundamentally new because everything you do must first be programmed into the game itself.
Because of these limitations, Salaggio argues that artists need to completely reimagine their relationship with AI tools just as Cory Arcangel did when he hacked a Super Mario Brothers cartridge to remove everything other than the clouds.
How we do move our relationship, as artists using DALLE2, away from consuming its choices, and into producing work — to steer this relationship away from machine dominance and toward our own desires? In other words: how do we begin to make our own games, rather than playing somebody else’s?
The most exciting possibilities for creating AI art are not in the nuance or fascinating minutiae of prompt engineering. The potential of AI art is yet to be realized. It will come about as artists learn to pull away from the call-and-response of the prompt window and its prizes.
When we defend tools like DALLE2 as if the raw product is an artistic expression of the one who types the prompt, we sacrifice some of that criticality in negotiating the lines between personal expression and technologically mediated desire. The prompt is an idea, but the image — the expression of that idea — is left to the machine.
Let’s embrace these outputs as a source of further play, not the end point.
Midjourney, which was, until very recently, built on top of the open source Stable Diffusion model, has an intentionally distinct style that is consistent across all of the images it produces. This is a deliberate choice the Midjourney developers made because it is a differentiator: the reason you would pay for Midjourney instead of using a free alternative is because you want the unique, proprietary style that Midjourney offers.
This might serve another purpose too. An AI image generator that has a recognizable “house style” is obviously not a neutral medium. It is not simply an unbiased extension of the artist but a tool with constraints, not fully under your control.
-
Stanislas Polu has some predictions about the state of large language models next year. The only prediction of his that I feel especially confident in myself is the following:
There will be an opensource Chinchilla-style LLM released this year at the level of text-davinci-*. Maybe not from the ones we expect🤔This will obliterate ChatGPT usage and enable various types of fine-tuning / soft-prompting and cost/speed improvements.
I would say that now, especially after the success of ChatGPT, an equivalent open source LLM will almost certainly be released in the next year. This will likely follow the same pattern as image generation AIs earlier this year: first, OpenAI released DALL-E 2 as a private beta. Then, a little while later, Stable Diffusion was released which, although it wasn’t quite as good as DALL-E, was free, open-source, and widely accessible. This allowed for an explosion of creative applications including photoshop plugins, 3D modeling plugins, and easy to install native frontend interfaces.
While I believe text generation AIs will have a similar moment early next year. The unfortunate truth is that running even a pre-trained text generation network requires significantly more computer memory than is required to run similarly sized image generation networks. This means we will probably not see early open-source text generation networks running natively on consumer hardware such as iPhones like we have with Stable Diffusion (although it is possible Apple will, once again, help with that).
My hope is that these developments in text-generation spur some much-needed innovation in household voice assistants which are increasingly feeling dated.
-
Onformative Studio shares its expirence using a generative AI to create 3D sculptures:
We were guided by the question of how our role as the designer is changing when human creativity and artificial intelligence co-create. In the course of the AI’s sculpting process we were inspired by the unpredictable strategies and outcomes of the reinforcement learning: an experimental approach par excellence, which we guided, observed and visualized.
Above all, we have also questioned our own role as creators. Rather than leaving creation to AI, we need to find ways to integrate it into the creative process. We take technology as a starting point, a tool, a source of inspiration and a creative partner. The human aspect is quite clear in this: We choose the rules and define the approximate output. However, in the end it was the interplay between our human choices and the agent’s ability to find the best solutions and occasionally surprise us. This made the process rewarding to us and shows the true potential of an AI based co-creation process.
This reminds me of some of the ideas Noah Smith and Roon laid out in their recent article about generative AI:
We think that the work that generative AI does will basically be “autocomplete for everything”.
What’s common to all of these visions is something we call the “sandwich” workflow. This is a three-step process. First, a human has a creative impulse, and gives the AI a prompt. The AI then generates a menu of options. The human then chooses an option, edits it, and adds any touches they like.
There’s a natural worry that prompting and editing are inherently less creative and fun than generating ideas yourself, and that this will make jobs more rote and mechanical.
Ultimately, though, we predict that lots of people will just change the way they think about individual creativity. Just as some modern sculptors use machine tools, and some modern artists use 3d rendering software, we think that some of the creators of the future will learn to see generative AI as just another tool – something that enhances creativity by freeing up human beings to think about different aspects of the creation.
I am optimistic that generative AI will continue to make creative expression of all kinds more accessible. At first, AI assisted design will be viewed as lower status or less authentic, like baking brownies using a pre-made box mix instead of “from scratch.” Later, though, once these technologies become more established, not using an AI will prompt discussion and warrant explanation — AI collaboration will be the norm. This is already the case with smartphone photography.
-
Matt Yglesias on how technological progress might change higher education:
The past couple of centuries have seen a steady increase in the market demand for certain kinds of skills. That’s meant people want to acquire these skills even if they don’t necessarily have tons of inherent motivation — they want training to earn a better living, and education as a formal process is a very useful motivational crutch. It’s at least possible that the next twist in IT will be to rapidly erode the demand for that kind of education, meaning people will be left primarily to learn things they are curious about where there is much less need for external motivation.
This is part of the reason why I believe fostering a strong and diverse set of intrinsic motivations is crucial at all levels of education. Whether or not the future Yglesias describes here comes to pass, students driven by intrinsic motivations are always going to be more passionate and engaged than students driven by extrinsic motivations.
-
Sam Kriss on how, as GPT models have become more accurate, they have become less compelling:
I tried using GPT-2 to write a novel. I let the AI choose the title, and it was absolutely insistent that it should be called “BONKERS FROM MY SLEEVE”, with the caps and quotation marks very much included. There was a Pynchonian array of bizzarely named characters (including the Birthday Skeletal Oddity, Thomas the Fishfaller, the Hideous Mien of Lesbian Jean, a ‘houndspicious’ Labradoodle named Bam Bam, and a neo-Nazi cult called ‘The Royal House of the Sun’), none of the episodes made any sense whatsoever, and major characters had a habit of abruptly dying and then popping up again with a different gender. But along the way it produced some incredible passages
…
GPT-2 was not intended as a machine for being silly, but that’s what it was—precisely because it wasn’t actually very good at generating ordinary text. The vast potential of all possible forms kept on seeping in around the edges, which is how it could generate such strange and beautiful strings of text. But GPT-3 and its applications have managed to close the lid on chaos.
…
There are plenty of funny ChatGPT screenshots floating around. But they’re funny because a human being has given the machine a funny prompt, and not because the machine has actually done anything particularly inventive. The fun and the comedy comes from the totally straight face with which the machine gives you the history of the Toothpaste Trojan War. But if you gave ChatGPT the freedom to plan out a novel, it would be a boring, formulaic novel, with tedious characters called Tim and Bob, a tight conventional plot, and a nice moral lesson at the end. GPT-4 is set to be released next year. A prediction: The more technologically advanced an AI becomes, the less likely it is to produce anything of artistic worth.
I could also see this as something that would help establish the validity of AI assisted artwork. As in “AI could never make something this inventive on its own, the artist must have played a large role in the artwork’s creation.”
-
Zero Trust Homework
Here’s an example of what homework might look like under this new paradigm. Imagine that a school acquires an AI software suite that students are expected to use for their answers about Hobbes or anything else; every answer that is generated is recorded so that teachers can instantly ascertain that students didn’t use a different system. Moreover, instead of futilely demanding that students write essays themselves, teachers insist on AI. Here’s the thing, though: the system will frequently give the wrong answers (and not just on accident — wrong answers will be often pushed out on purpose); the real skill in the homework assignment will be in verifying the answers the system churns out — learning how to be a verifier and an editor, instead of a regurgitator.
I am not sure I fully agree with Ben’s proposal here but, at the same time, I am having trouble coming up with any coherent solutions for homework / assessments that truly account for the AI we have today — let alone what we will have 10 years from now.
Ultimately, I am hopeful these advances in AI will push us to re-evaluate our current approach to education and lead us towards more meaningful, interdisciplinary, and practical approaches in the future.
{kind=link}
{kind=link}
subscribe via RSS