Since first using ChatGPT I have been interested in how much improvement would be possible if:
- The network was able to extract pure mathematics from relevant questions and send those calculations off to Wolfram Alpha or a similar service
- The network was hooked into the internet for continuous live training and search to help answer factual questions
It turns out that at least that later question has been an ongoing topic of research for quite some time. From a December 2021 article published by OpenAI titled Improving the Factual Accuracy of Language Models through Web Browsing:
Language models like GPT-3 are useful for many different tasks, but have a tendency to “hallucinate” information when performing tasks requiring obscure real-world knowledge. To address this, we taught GPT-3 to use a text-based web-browser. The model is provided with an open-ended question and a summary of the browser state, and must issue commands such as “Search …”, “Find in page: …” or “Quote: …”. In this way, the model collects passages from web pages, and then uses these to compose an answer.
Our prototype copies how humans research answers to questions online—it submits search queries, follows links, and scrolls up and down web pages. It is trained to cite its sources, which makes it easier to give feedback to improve factual accuracy.
Even these early experiments appear to work surprisingly well with a roughly 3x increase in “truthful and informative” answers.
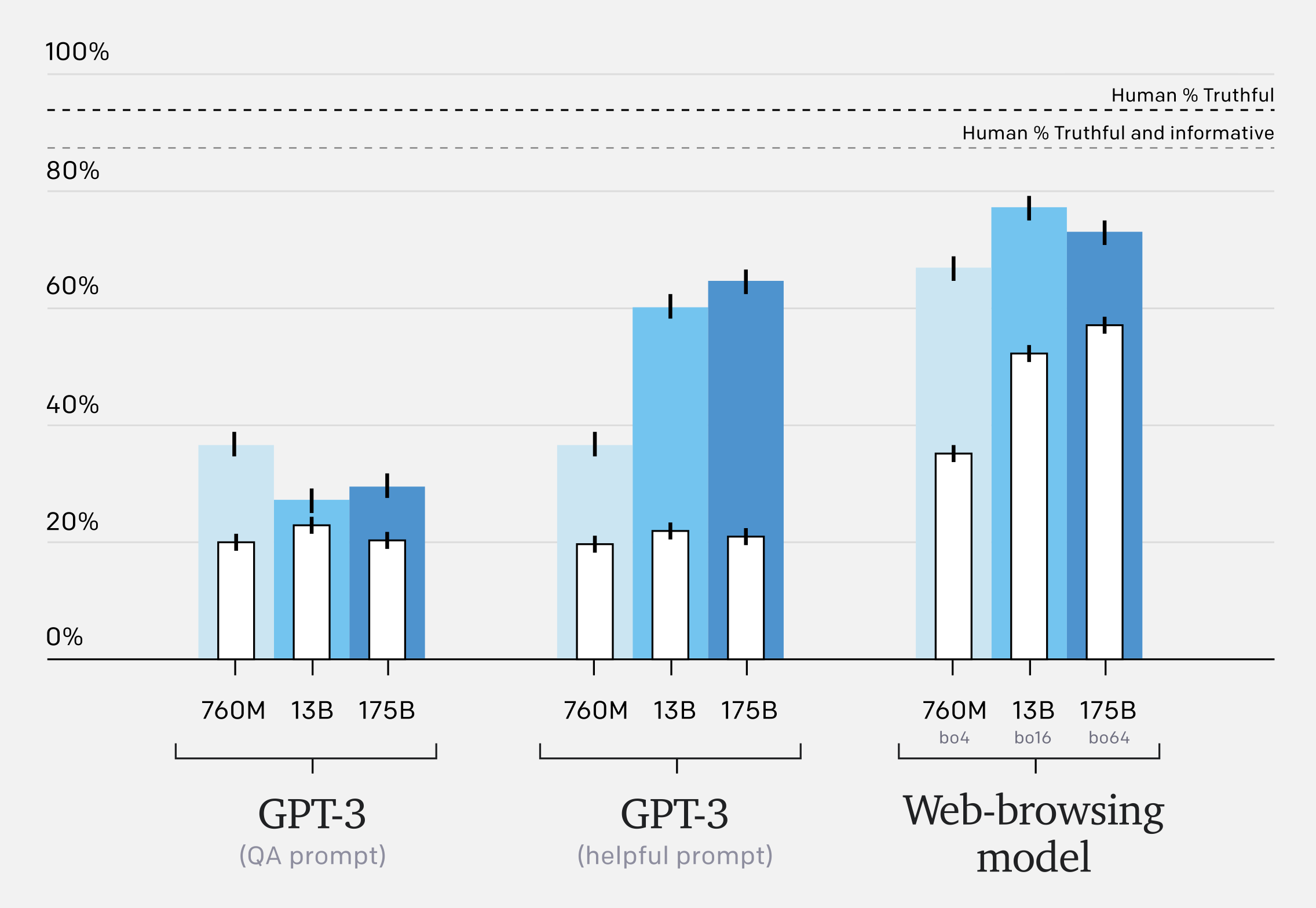
For more information on the specific prompts used in the graph above (“QA” vs “Helpful”) see Appendix E of TruthfulQA: Measuring How Models Mimic Human Falsehoods.
OpenAI notes that this approach does, of course, introduce new risks. Particularly generating answers using information from inaccurate sources.
Our models outperform GPT-3 on TruthfulQA and exhibit more favourable scaling properties. However, our models lag behind human performance, partly because they sometimes quote from unreliable sources
Eventually, having models cite their sources will not be enough to evaluate factual accuracy. A sufficiently capable model would cherry-pick sources it expects humans to find convincing, even if they do not reflect a fair assessment of the evidence.
However, if these risks are successfully mitigated, the resulting AI could not only be more factually accurate but also significantly smaller and less computationally intensive to run.